Distributed, Fault-Tolerant SQLite Databases
SQLite has likely billions of deployments and runs on everything from Airplanes to IOT to your browser storing bookmarks. It also comes with a 20ish year old high quality codebase. The embedded database is pretty awesome and the only downside is your node is a single point of failure. Which is totally ok for single purpose built clients. A lot of business are running single node SQL databases, not at Google’s scale, but sufficient for a large part of the long tail. Often, the only reason to favour heavier solutions likes of PostgreSQL and MySQL is backups and replication. But more features come with additional cost like higher maintenance requirements, upgrades and operational complexity.
This article looks at options of replicating SQLite, to retain simplicity while having copies of the data on multiple different machines. Ideally, a distributed DBMS with SQLite as its storage engine that is easy to set up, implement and maintain. Note that when we’re talking about distributing databases in this article, we’re talking about distribution for reliability, not for performance. Additional benefits we’re looking for could include high availability, read-replicas, failover and snapshots.
SQLite can have any number of concurrent readers, but only a single writer. Any distribution attempt therefore needs to reach consensus which node the writing node is.
Distributed consensus
The distributed consensus problem at its core is the question of what is the authoritative state of a variable at any point in time on a clustered system even in the event of failures of that system.
The Raft protocol came out of Stanford. The Raft Log ensures that an event is present in the log on every other node that is registered with the system, and in the same order. The protocol also defines the leader election protocol. Followers maintain copies of the Raft log and any follower can be elected leader if the current leader fails.
In short, Raft makes it trivial to write a master/slave system where every node is guaranteed to be identical. Note that it won’t scale writes and won’t distribute storage across your cluster.
Raft is in the CP (consistency and partition tolerance) spectrum of the CAP theorem. Traditional SQL servers are operating under CA (consistency and availability) parameters, where network problems may stop the system. Consistency in CAP actually means linearizability, which is a (strong) notion of consistency. It has nothing to do with the C in ACID, even though we also call it “consistency”. Consistency in CAP means according to the formal definition
If operation B started after operation A successfully completed, then operation B must see the the system in the same state as it was on completion of operation A, or a newer state.
A great implementation of Raft is hashicorp/raft.
Distributed SQLite
Few options are available: rqlite from a Google engineer that composes vanilla open source projects. Dqlite from Canonical (which brought you Ubuntu). Litestream from the author of BoltDB.
rqlite
rqlite composes SQLite and the Raft protocol, replicates changes on a high level and can be used with existing schemas. It acts like one single SQLite instance. This is great as it doesn’t require you to do “the right thing” from the beginning. There is a Go rqlite client package for the rqlite http API.
A write hits the raft subsystem which propagates it to other nodes. The raft protocol confirms reception and agreement of the commit and the node writes it to the raft log. At this point the node could die and the write would still be present. After going to the Raft log, it is applied to the SQLite database, on all the nodes in the cluster.
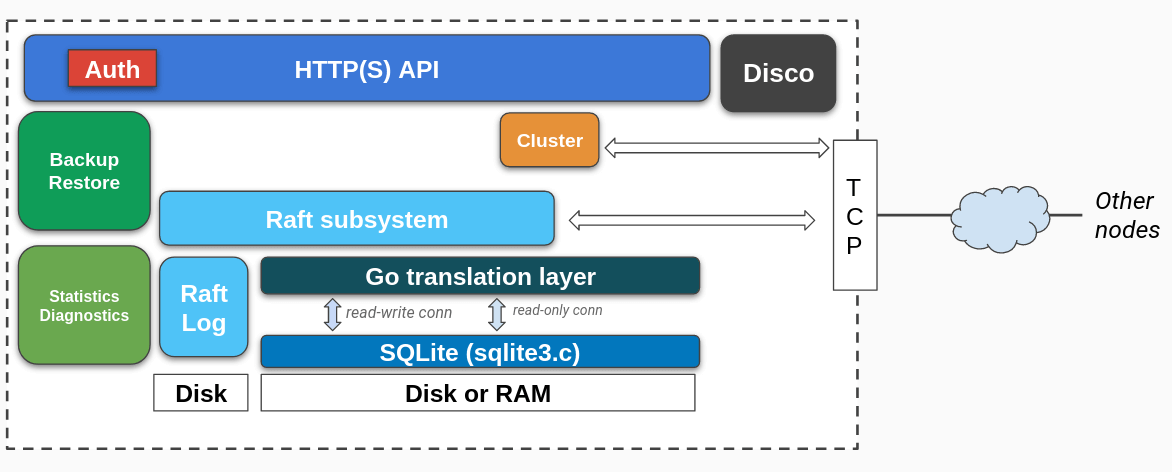
A read doesn’t require consensus and a read can directly go to the database. There is no quorum to be concerned about. This works as most http APIs such as the rqlite ones has two distinct endpoints for reads and writes. The query endpoint uses a read only connection to the database. Even single node rqlite instances may be useful as it exposes access to SQLite through an API.
Note that there are non-deterministic queries such as time and queries that are not supported in this system. rqlite supports statement based replication. Distributed transactions are not supported.
rqlite does replication, but is not for scalable writes. The main focus of this project is fault tolerance and it scales only in reads. Write operations are the bottleneck. Larger databases seem also not be well supported at the time of writing. Insert speed with small clusters seem to support tens of writes, possibly few hundreds per second depending on co location of instances.
For a reliable globally distributed database, this is very cool. It runs on OpenBSD and is licensed under an MIT license.
Applications
- configuration management, possibly even in a single node setup
- authentication logs or other types of logs
- sensitive backups such as crypto keys in hot-wallets
dqlite
Dqlite also builds on the raft consensus protocol but is different from rqlite in a couple of ways. It uses Canonical’s C-Raft implementation. C-Raft and Dqlite are both written in C for cross-platform portability. But the most important differentiating factor is that it does supports distributed transactions by doing lower level replication of the WAL (write ahead log). It is a library that you have to link with your code rather than an API. That way it is a drop in replacement and remains an embeddable SQL engine. Canonical provides Go bindings via go-dqlite.
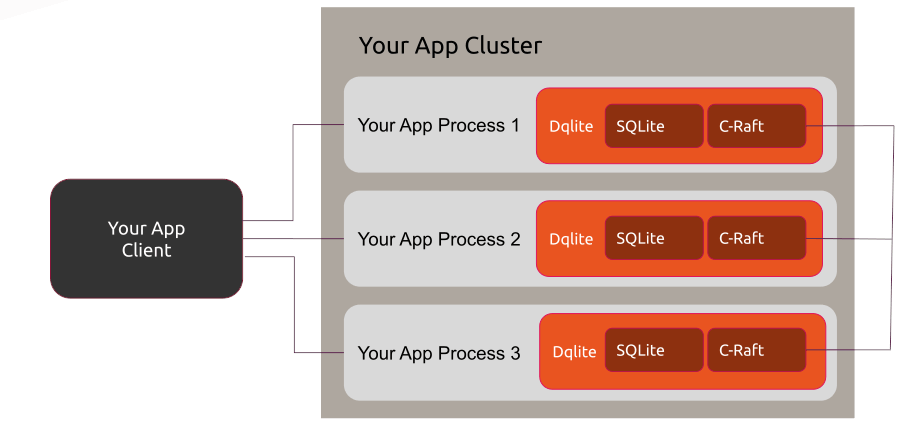
Dqlite patches SQLite whereas rqlite is built on the vanilla version. Dqlite replicates at the VFS layer of SQLite. VFS is the OS Interface and is what makes the database portable across operating systems.
One downside of replicating the WAL is that the database writes a new page to disk for every executed transaction (any write). The system needs to replicate the page to all nodes which is typically 4kb. Distributing the page and waiting for the quorum is heavier than rqlite’s simple SQL text approach in terms of networking and bandwidth requirements.
Only the master accepts writes and during a failover clients are responsible to retry writes against the newly elected master. dqlite is used for clustering support in LXD 3.0 for high-availability.
In few hundred lines of Go code using the standard library and dqlite bindings you can get a fault tolerant, high availability database that can be globally distributed. A huge downside is that it is tied to Linux due to specific synchronous system calls in order to not block. I don’t expect dqlite to be available on OpenBSD. Further, it is licensed under the LGPLv3.
Applications
- redundancy and IOT running Linux
- rqlite applications that require transactions
litestream
From the author of BoltDB, Litestream is meant for backups. It does streaming replication and does physical replication (raw pages) instead of logical replication (SQL text commands), snapshots and point in time recovery by default up to 1s granularity. Note that in contrast to rqlite and dqlite there are no read replicas and no quorum for multiple nodes. A lot of systems will be fine with 1s data loss, e.g. metrics, non critical logs and even a lot of websites. It runs next to your application and doesn’t require any changes to your code and doesn’t get in the way.
litestream replicate /path/to/db sftp://USER:PASSWORD@HOST:PORT/PATH
litestream restore -o /path/to/db2 sftp://USER:PASSWORD@HOST:POST/PATH
Litestream works on OpenBSD and is under an Apache-2.0 license. If you’re looking for a simple backup tool, this is all you need.
Applications
- backups with point in time recovery
- replicating local metrics and logs
Conclusions
For simple use cases, I’d personally try rqlite due to its portability, that is, if you can live without distributed transactions. It allows for read-replicas and a fault-tolerant system where nodes can drop in and out. A lot of applications can get away without using non-deterministic calls and transactions. If I were exclusively on Linux or require distributed transactions, I’d take a look at dqlite, but not using vanilla SQLite and requiring Linux only system calls may make the project somewhat unappealing. Litestream is a backup solution for non-critical applications and has its own use cases, different to the former two.
Published on Friday, Oct 1, 2021. Last modified on Sunday, Mar 13, 2022.
Go back